How AI Roleplay Programs Work: A Guide to Measurement and Hyper-Personalized Upskilling
June 2, 2026
14 minutes
HR leaders are deploying AI roleplay programs at scale, and they are doing it for two reasons that used to be considered separate problems.
The first is measurement. A traditional assessment center can put a few dozen people through structured scenarios, score them against a competency framework, and produce a skill profile. The output is high-quality but expensive (roughly €1,000 to €2,000 per participant) and impossible to repeat at frequency. You measure once, at one point in time, and hope the result is still relevant a year later.
An AI roleplay program performs the same kind of behavioral measurement, against the same kind of competency framework, for thousands of people at once, and as often as the program runs. That changes what an organization can know about its own workforce.
The second reason is hyper-personalized upskilling. Once skill levels can be measured continuously for every participant, each person can be routed to the practice that matters for them specifically. Someone weak in objection handling gets more roleplays with skeptical personas. Someone strong in discovery but inconsistent under pressure gets harder scenarios. The program adapts. Measurement and practice form a single loop.
Both functions depend on the same underlying mechanism: an AI that scores conversations reliably enough that the resulting numbers can stand up to scrutiny from participants, managers, works councils, and legal teams. This guide explains how the scoring works, what makes it trustworthy, and how it enables the personalization that distinguishes AI roleplay programs from the legacy methods they replace.
The short answer: AI roleplay programs become operationally useful when three things are in place. First, the scoring rubric uses Behaviorally Anchored Rating Scales (BARS), the established methodology for making subjective ratings consistent. Second, the AI is calibrated against expert human raters, and only ships when its scores match expert consensus closely. Third, every score traces back to specific moments in the transcript. With those three layers in place, the AI’s output is reliable enough to drive both individual upskilling decisions and program-level reporting.
Why HR Leaders Are Rolling Out AI Roleplay Programs
The measurement problem in large organizations has existed for decades. You can hire well, train hard, and still have no reliable way to know whether your people are actually getting better at the things you said the program would develop.
Three things have historically stood in the way.
The cost of structured assessment. A formal assessment center is the gold standard for behavioral measurement, but at €1,000 to €2,000 per participant, it is reserved for senior hires, succession candidates, and a small slice of high potentials. Most of the workforce is never assessed at this level of rigor.
The inconsistency of human rating. Even when assessments do happen, two assessors watching the same conversation often disagree on how it went. This is not a recent problem. It has been the central challenge of psychometric assessment since the 1960s.
The static nature of measurement. A traditional assessment is a one-shot event. You score someone in March and treat that score as ground truth until the next cycle. But behavior changes (or doesn’t) week to week, and a one-time snapshot says nothing about trajectory.
AI roleplay programs address all three. They are cheap enough to run for the entire workforce, consistent enough to produce comparable scores across people and time, and continuous enough that you measure development as it happens, not in retrospect.
What makes them work is the scoring layer underneath. Without rigorous scoring, an AI roleplay program is just expensive practice. With rigorous scoring, it becomes a measurement system that also happens to provide the practice.
What the AI Is Actually Scoring
When a participant uses Coachello AI Avatar Roleplays, the experience looks like a real conversation. They speak (typed or voice) with an AI character. A skeptical CFO. A loyal-to-incumbent buyer. A frustrated employee. Whoever fits the scenario your L&D team has configured. Most roleplays run five to fifteen minutes.
Behind the scenes, every word is captured as a transcript with timestamps and speaker turns. The transcript is the raw material. Every downstream score traces back to it.
The AI then reads the transcript and asks, criterion by criterion, “did the participant do this thing? How well?”
A criterion is a specific, observable behavior. Examples from a typical sales rubric:
- “Asked layered follow-up questions”
- “Identified the economic decision-maker”
- “Framed cost in terms of business outcome rather than list price”
- “Acknowledged the prospect’s objection before responding”
These criteria are not invented by Coachello. They come from your sales playbook, your leadership framework, or whatever competency model your organization already uses. The system operationalizes them. You decide what good looks like.
Notice what the AI does not do. It does not produce a single overall grade for the conversation. It scores each criterion separately. This separation is deliberate, and it is the foundation of everything that follows.
Why Behavioral Anchors Make Scoring Trustworthy
Here is the issue with asking any rater (human or AI) to judge something fuzzy like “active listening”. Two raters will score the same conversation differently because they have different mental pictures of what good looks like. One thinks lots of paraphrasing is the standard. The other thinks asking sharp questions matters more. Both views are partly right. Neither view is auditable.
The fix was invented in 1963 by two industrial psychologists, Smith and Kendall. The method is called Behaviorally Anchored Rating Scales, or BARS. Instead of asking “rate this person’s listening from 1 to 5,” you write out in advance what each level actually looks like, in concrete behavioral terms.
For active listening, the anchors might read:
Level 1. Talks over the prospect, doesn’t acknowledge their points.
Level 3. Lets the prospect finish, occasionally paraphrases what they said.
Level 5. Paraphrases accurately, asks follow-ups that build on the prospect’s exact wording, surfaces what was left unsaid.
Now scoring is no longer a matter of opinion. It is a pattern-match against explicit descriptions. Two evaluations of the same transcript converge, because both are matching against the same anchors rather than against a private mental model.
This is the foundation of every assessment methodology that holds up in employment tribunals, in works councils, and in HR audits. It is the standard in psychometric testing for the same reason. BARS is over sixty years old and still in use because no one has found a better way to make subjective judgments consistent.
Coachello did not invent the methodology. The methodology has been validated by decades of peer-reviewed research. What we built is the implementation: a system that applies BARS computably, in real time, against millions of words of roleplay transcript.
How the AI Is Calibrated Against Human Experts
A fair next question. Even if the methodology is sound, how do we know the AI is applying it correctly? Maybe it scores everyone too generously. Maybe it has blind spots. Maybe it picks up surface features like vocabulary or sentence length, instead of substance.
The answer is calibration against humans. The process works as follows.
Coachello maintains a gold set. This is a collection of roleplay transcripts that have been carefully scored by human experts in the relevant domain: executive coaches, sales leaders, learning specialists. Each transcript gets multiple expert ratings, and the consensus is used as the reference. The gold set grows over time and currently sits in the hundreds of samples per competency framework.
When the AI scoring model is updated (which happens regularly), the new version is run against the gold set, and its scores are compared to the expert consensus. If the AI matches consensus closely, the update ships. If it does not, it does not. The headline metric is the percentage of items where the AI is within one point of expert consensus on a 5-point scale. The target is above 90%.
A second metric is inter-rater agreement, expressed as a correlation coefficient. A score of r = 1.0 means the AI and human experts always agree. A score of r = 0.0 is random. In professional assessment work, human-to-human agreement typically sits between r = 0.70 and r = 0.85. The target for the AI is to match expert raters at least as consistently as expert raters match each other. The AI should not be introducing noise. It should be doing the same job, faster, and at scale.
In practice, this means the AI is not replacing expert judgment. It is a faithful echo of what your best human raters would do, applied at a scale no human team could achieve.
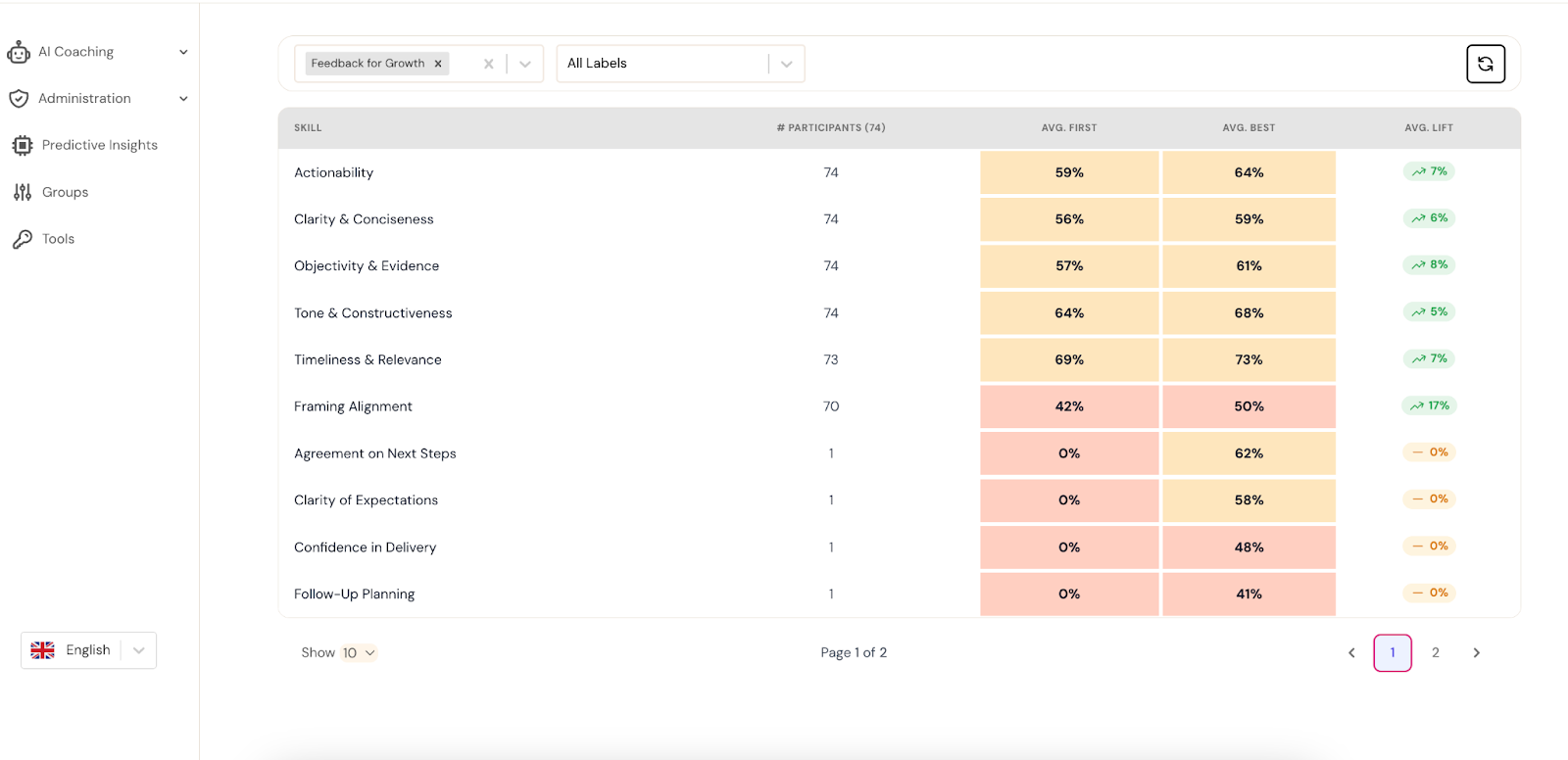
From Criterion Scores to Skill Profiles
A typical roleplay generates around fifteen criterion scores. That is too granular to be useful on its own. Nobody wants a coaching report with fifteen columns.
This is where the skill taxonomy comes in. A skill is the unit of capability your organization actually thinks about: discovery questioning, objection handling, competitive positioning, executive presence. Most programs have six to ten of these, and they are what your L&D team designs content around.
Criteria roll up into skills. You decide which criteria belong to which skill, and you assign weights. A Discovery questioning skill might be composed of:
- “Asked open questions” (30% weight)
- “Followed up on vague answers” (40%)
- “Explored consequences of inaction” (30%)
The system enforces the math. You provide the meaning.
Each participant ends up with a skill profile rather than a list of raw scores. Six or seven skill-level numbers, each grounded in the underlying criteria, and each interpretable by a manager. “Sarah is strong in discovery but weak in objection handling” is a sentence you can act on. “Sarah scored 62 on item 7 and 48 on item 11” is a spreadsheet nobody reads.
The skill profile is the bridge between measurement and what happens next.
How Measurement Enables Hyper-Personalized Upskilling
This is where AI roleplay programs do something traditional assessment cannot. The skill profile is not just a report. It is also the input that drives what each participant practices next.
The personalization loop works like this.
The participant starts with a baseline assessment. The system measures their current skill profile across the competency framework you have configured. This is the diagnostic step.
The program then routes them to roleplays that target their lowest-scoring skills. Someone weak in objection handling is sent into more scenarios with skeptical CFOs and loyal-to-incumbent buyers. Someone strong in discovery is given less of that, and more of whatever they need. The personas, the scenarios, and the difficulty level are all matched to the individual gap profile rather than to a generic program calendar that everyone follows in lockstep.
As the participant practices, the system collects more transcripts and updates the skill profile. Skills that are improving show measurable lift. Skills that are not yet developing get more practice surfaced. The loop closes and repeats.
This is what hyper-personalized actually means in practice. It is not a marketing word. It is the operational difference between a program where every participant follows the same module sequence and a program where each participant follows a path shaped by their own measured gaps.
The personalization only works if the underlying measurement is reliable. Inaccurate scoring produces inaccurate routing. This is why the methodology layer (BARS, calibration, audit trail) is not optional rigor for the measurement use case. It is what makes the personalization use case possible at all.
From Individuals to Cohort Patterns
A skill score for one person on one roleplay is data. A skill score for one person across ten roleplays is a profile. Skill scores aggregated across an entire cohort, over time, is where program-level decisions get made.
The aggregation works as you would expect.
- Sample sizes are tracked. You know how many roleplays each person has done, so you can tell which scores are reliable and which are still early.
- Distributions are surfaced, not just averages. The median and spread of objection handling across your EMEA sales team tells you more than the average alone.
- Change over time is measured with statistical confidence. If a cohort’s average rises from 58 to 72 between the start and end of a program, the system shows you whether that change is likely signal or likely noise.
For comparisons across teams, regions, or roles, the system applies standard tests for whether differences are likely meaningful. When someone asks, “is our German team really better at competitive positioning than our French team?”, the honest answer depends on sample size and effect size, not just on raw numbers. Both are shown.
Cohort analytics is what makes the difference between a roleplay tool and a program-level measurement system. It is also what HR leaders need when they sit down with the CHRO or the CFO to justify the program’s investment. For more on what behavior change at this scale actually looks like, see our research on why 70% of leadership training budget is wasted within months.
The Audit Trail: Why Every Score Holds Up
Every score the system produces, every criterion score, every skill score, every cohort comparison, is traceable back to specific moments in specific transcripts. A participant can ask, “why did I get a 3 instead of a 5 on objection handling?”, and the system surfaces the exact lines from the conversation that drove that score, alongside the BARS descriptions for level 3 and level 5.
This is what defensibility looks like in practice. It is not a marketing claim. It is an architectural choice. The system was built so that no number exists without its evidence attached.
If an HR leader is asked by a participant, a line manager, or a works council representative, “where does this score come from?”, the answer is always a finger pointing at specific words on a specific page of a specific transcript.
The same architecture handles disputes. A participant who disagrees with a score can flag it. An admin pulls up the underlying transcript, sees the AI’s reasoning, and either confirms or overrides. Overrides feed back into the calibration set, so the system learns from the cases where it disagreed with human judgment.
Questions HR Leaders Tend to Ask
A handful of questions come up in most evaluations of AI roleplay programs. The honest answers are below.
What if the AI is biased?
Bias is a real concern in any AI-driven assessment. It is mitigated three ways.
First, behavioral anchors describe observable behaviors rather than personality traits, which reduces the surface area for bias to operate. Second, the calibration gold set is reviewed for demographic balance, so the AI is trained against a representative reference. Third, scoring distributions across demographic groups are monitored in production, and anomalies are flagged for human review.
No assessment system can honestly claim zero bias. The risk is actively managed, not ignored.
Can a participant challenge their score?
Yes, by design. The transcript and the AI’s reasoning are visible to the participant. They can flag any score they disagree with, and an admin will review. Overrides feed back into the system, so it learns over time.
What about regulatory risk: GDPR, the EU AI Act, works councils?
Coachello’s scoring approach aligns with ISO 10667, the international standard for assessment service delivery. It is built on BARS, which is widely accepted in employment-related assessment law and practice in both the EU and the US.
Under the EU AI Act, AI used in employment contexts is treated as high-risk and requires transparency plus human oversight. Both are built into the system. Specific compliance posture depends on your jurisdiction and rollout, and our team is happy to walk through it.
How is this different from a traditional assessment center?
Same goal: observe behavior in a structured scenario, score it against a rubric, aggregate into a profile. Three differences in execution.
- Scale. An assessment center handles a few dozen people per year. An AI roleplay program handles thousands.
- Repeatability. An assessment center is a one-shot event. An AI roleplay program generates repeated measurements over time, which is what makes skill development visible.
- Cost. An assessment center runs €1,000 to €2,000 per participant. An AI roleplay program is closer to a software subscription.
The methodology is the same. The economics and the operating model are not.
What AI Roleplay Programs Aren’t
Honesty is part of defensibility. Here is what an AI roleplay program is not, even when the scoring is rigorous.
It is not a personality test. The system measures observable behaviors in structured scenarios, not innate traits. A participant who scores low on objection handling has not failed a personality assessment. They have shown a behavioral pattern in roleplays that points to a development area.
It is not a performance review. The scores describe behaviors in roleplay scenarios, which correlate with (but are not identical to) real-world job performance. Anyone presenting roleplay scores as proof of job performance has overstepped what the data supports.
It is not a substitute for human judgment in high-stakes decisions. The scores are a powerful input into development, coaching, and program evaluation. They should not be the sole basis for promotion, termination, or compensation decisions. Not because the scores are unreliable, but because high-stakes employment decisions deserve human deliberation, and any responsible vendor will say the same.
What an AI Roleplay Program Is, in One Paragraph
An AI roleplay program, done well, is two things at once. It is a measurement system that produces continuous, comparable, defensible skill data across the entire workforce, at a price point that makes universal assessment feasible. And it is an upskilling system that uses those measurements to give each person the practice that will close their specific gaps. The two functions reinforce each other. Better measurement enables better personalization. Better personalization generates more measurement data. The cycle compounds.
The methodology underneath (BARS, expert calibration, full audit trail) is what makes both halves work. Without rigorous scoring, the measurement is unreliable, and the personalization is guesswork. With it, you get a system that holds up under scrutiny and produces visible skill development over time.
Ready to See It Work?
If you are rolling out an AI roleplay program at scale, or evaluating whether to, book a free consulting call with our team. We will walk through how scoring and personalization work on your specific competency framework, and show you the audit trail in action on a real transcript.
You can also explore Coachello AI Avatar Roleplays directly, or read our Assessment Debrief Guide for more on what happens after a participant’s score arrives.
Frequently Asked Questions
What is an AI roleplay program?
An AI roleplay program is a workplace upskilling system in which participants practice real conversations (sales discovery, difficult feedback, executive presentations, and so on) with AI-driven characters (text, vocal or real-life-like AI avatars). Each conversation is scored against a behavioral rubric to produce a skill profile, which the system then uses to personalize the participant’s next practice scenario. It combines measurement and practice in a single operating loop.
What is BARS in HR assessment?
BARS stands for Behaviorally Anchored Rating Scales. It is an assessment methodology developed in 1963 by Smith and Kendall that grounds subjective ratings in concrete behavioral descriptions at each score level, rather than asking raters to score on a vague numerical scale. It is a standard methodology in HR assessment and is widely accepted in employment law contexts.
How accurate is AI scoring compared to human raters?
When properly calibrated, modern AI scoring systems can match expert human consensus within one point on a 5-point scale in over 90% of cases. Inter-rater agreement (the measure of how consistently the AI aligns with experts) typically targets r = 0.85 or higher, which sits at the upper end of what human experts achieve when compared to each other.
How does AI roleplay personalization actually work?
The system runs a baseline assessment to measure the participant’s starting skill profile. It then routes them to roleplay scenarios, personas, and difficulty levels that target their lowest-scoring skills. As they practice, the skill profile updates, and the routing adapts. The personalization is driven by continuous measurement, not by a fixed module sequence.
Is AI roleplay scoring compliant with the EU AI Act and GDPR?
The scoring approach aligns with ISO 10667 (the international standard for assessment service delivery) and includes transparency plus human oversight by design, both of which the EU AI Act requires for AI used in employment contexts. Specific compliance posture depends on your jurisdiction and rollout, which our team can walk through with you.
How long does it take to set up an AI roleplay program for a custom competency framework?
Most organizations can have a customized rubric, skill taxonomy, and persona set operational within two to four weeks. The longest part of setup is usually defining what good looks like in behavioral terms for your specific organization, which is the configuration of the BARS anchors. Coachello works with your L&D leads to translate your existing competency model into operational anchors.
Share this article


Unlock the Power of Coaching
Enhance leadership, boost performance, and drive growth with AI-powered and human-led coaching. Read articles from coaches, psychologists, and business leaders to help you boost performance, improve well-being, and lead with confidence.

Enter your email and we’ll send you the brochure